
Last week, I had written a summary of Nvidia’s Turing RTX line-up of graphics cards, including their specs, launch dates, and prices. For a high level overview of that, check out the article here. Now that we’re one week removed from the keynote, however, we have had a chance to digest more of the information that was discussed, in addition to (attempting to) understand the new technology introduced.
There is simply much we do not know about the RTX 2070, 2080, and 2080 Ti. The makeup of the GPUs to the technologies they’ll support is quite simply unprecedented in consumer GPUs. This article will be my attempt to deconstruct a lot of the technical underpinnings discussed in order for us to get a better understanding on these technologies.
It should be said that I am not an expert on these topics by any means. There will be some speculation here. As a result, I urge everyone to wait for independent benchmarks and simply not take Nvidia at their word. However, my hope is that after reading this article, you come away with a better understanding of the core functionalities and technologies at play in Turing RTX.
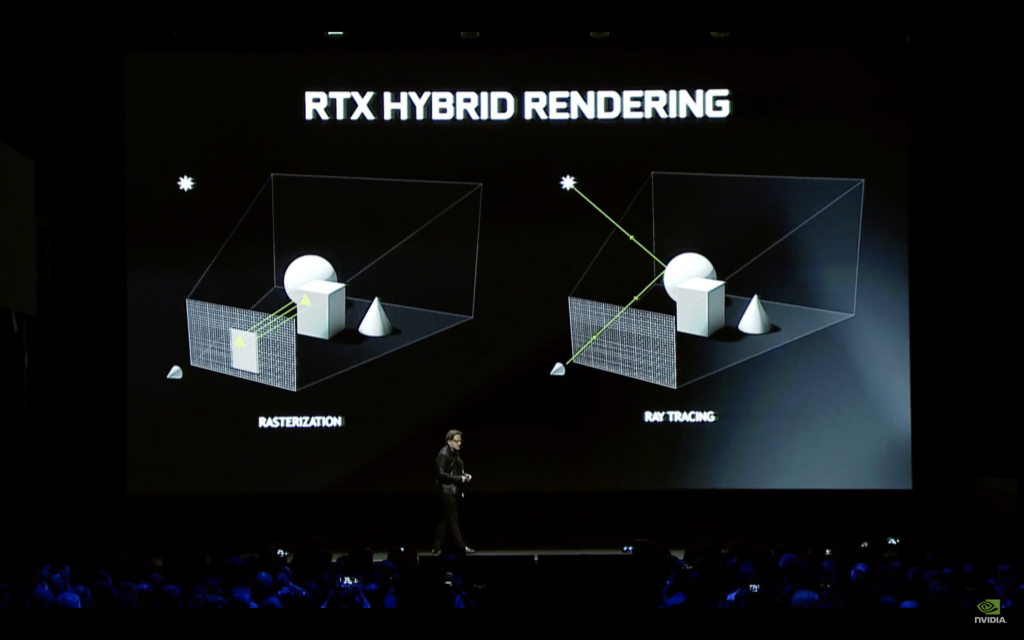
If you recall from Nvidia’s keynote, Turing is set to handle ray tracing (RT core), AI (Tensor core), and traditional compute operations (Turing SM). But before we dive too deep into these technologies, it’s important we have a common vocabulary from which to establish our baseline. The RTX GPUs are all about ray tracing. This is completely different to how games have been rendered for decades. The technique that has been a mainstay all these years is called rasterization.
Rasterization is effectively taking the 3D world vertices and projecting them into a 2D pixel plane, otherwise known as a screen-space. This projection leaves a silhouette of a triangle. You then test which one of the pixels are in that triangle.
Having been used for decades, rasterization has benefits and limitations. Arguably the biggest benefit is the phenomenal parallelization allowed with rasterization. This parallelization is what GPUs are extremely efficient at.
Rasterization is not without its limitations, no more evident in lighting. Every time you want to light the scene, you need to project light from that light source. In rasterization, handling two or three lights is fine. However, handling an area light (a single light source like the sun, for example) is a problem because that area light is effectively an infinite number of light sources interacting with everything in the scene. Everything in the scene would be a lighting surface, i.e. global illumination. Therefore, the number of lights you’d have to cast inside that scene would increase dramatically. This is simply unfeasible as it becomes extremely expensive computationally.
This is where ray tracing comes in. Ray tracing is simply tracing the path of each of those light particles and calculating how they interact with the objects in your scene. Because this ray tracing is mathematically and physically correct, it can very easily maintain the real-world properties of the objects it hits, the shadows it creates, and the reflections it creates. For example, you can very easily imagine that a wooden surface would look more diffuse than a more reflective surface like metal. You expect this because this is how wood and metal behave in real-life.
In short, shadows, reflections, and light all look and behave like they do in real-life. You are sending out a ray of light intersecting a pixel at the screen-space and entering the world looking for a triangle it would intersect with.

Ray tracing has been pretty much impossible on consumer grade hardware, so developers have had to come up with clever tricks to emulate the behavior of light. The three most common (though not exhaustive) methods are reflection probes, cubemaps, and screen-space reflections (SSR).
A reflection probe is similar to a camera, capturing a view of its surroundings in all directions. This captured data is stored as a cubemap, essentially a 2D capture of a 3D environment, stored as a collection of six textures (hence, “cube”) to display the environment in the up, down, forward, back, left, right positions.
Cubemaps are then used on traditionally reflective surfaces like windows to simulate a reflection. Problem is, because this data is essentially baked — remember it’s effectively a snapshot — it’s not real-time and thus cannot reflect the current environment accurately. For example, an explosion on a street will not be reflected on a cubemapped surface like the windows of a bus stop.
Developers can mitigate this somewhat by utilizing screen-space reflections. However, SSR too has its limitations. Because SSR only generates reflections for what is in the current screen-space, any occluded objects are not reflected. Objects can be occluded by other objects, or by simply tilting your camera. So for example, an explosion happening behind you, thus not in the screen-space, will not be reflected on that bus stop window in front you.
Finally, you’ve probably heard the term “TFLOPS” or “tera FLOPS.” In computing, this is used to measure the performance of hardware. A FLOP is simply “floating point operation per second.” Therefore, TFLOPS is trillion floating point operations per second.
But what exactly is a floating point? Very simply (and I do mean very simply), a floating point value is a representation of a real number as bits. The higher the precision of this number, the greater the accuracy. This is where you’ll see terms like FP32 and FP16. FP32 is 32 bits (or 4 bytes) of memory versus FP16 which is 16 bits (or 2 bytes) of memory. FP32 is most common for computer graphics and is also known as single precision, while FP16 is known as half precision. The greater the precision, the fewer computational operations you can perform. In other words, measuring performance at FP32 will be exactly one half of measuring performance at FP16.

With this in hand, let’s take a closer look at the Turing GPU itself. Nvidia breaks down the GPU in three distinct cores: The Turing SM, RT core, and Tensor core. These three cores all perform distinct functions, and it’s here where Turing completely deviates from previous architectures. Previous architectures only have the SM.
So…what is an SM? An SM is a streaming multiprocessor. The Turing SM can do independent floating point and integer operations concurrently. You use floating point to calculate color, for example. And you can use integer operations to calculate addresses to run shader programs to then calculate things like subsurface scattering at the same time.
This ability to independently handle floating point and integer operations is completely different from previous architectures that could only perform floating point operations. Turing also has new unified cache architecture with double the bandwidth of the previous generation (Pascal).
Because of this, the Turing SM is simply more efficient and powerful compared to a Pascal SM. Nvidia says Turing SM is 1.5x more efficient than previous generations, which independent benchmarks will need to verify. As a result of all this, the Turing SM outputs 14 TFLOPS of FP32 + 14 TIPS (Trillion Integer Operations Per Second). Additionally, the Turing SM can handle Variable Rate Shading to enable foveated rendering. Foveated render is a method to better use GPU power to more accurately render in greater detail where your eyes are looking, which is very useful for VR applications.
The RT core is the ray tracing core. Per Nvidia, it’s built to hand up to 10 Giga rays/second. The 1080 Ti capable of 1 Giga rays/second. So when you see Nvidia touting Turing as having 10x the performance of one 1080 Ti, this is what they mean. It does not mean that this one Turing GPU is 10x more powerful than one 1080 Ti. Turing is simply 10x as fast in ray tracing applications than a 1080 Ti. This RT core can also handle BVH tree traversal (more on this below) and Ray Triangle Intersection testing.
The Tensor core runs AI processing, deep learning, and the like. Per Nvidia, it can perform 110 TFLOPS FP16, 220 TOPS FP8, and 440 TOPS FP4.

Like I mentioned in my article last week, Nvidia has created a new metric by which to measure performance of these Turing RTX GPUs, called RTX-OPS. This is simply an aggregate of the weighted performance contributions of the Tensor cores, RT Cores, and SM cores and shaders. RT core handle ray tracing, the SM handles INT32 and FP32 shading, and Tensor core handles DNN (deep neural networking) processing. Turing can also leverage AI (Tensor cores) to correctly generate any missing pixels to fill out a frame.
Nvidia says when they aggregate this, they get 78T RTX-OPS. It should be noted that right now, I have no clue how they’re weighing each of these cores, and I don’t believe that information has been published as of this writing. Jen-Hsun also said that comparing this to Titan X, the Titan X can perform 12T RTX-OPS. This is misleading because the calculation of an RTX-OP involves Tensor cores and RT cores. These are things that Pascal simply doesn’t have. It’s not a one-to-one comparison like Jen-Hsun would have you believe.

I mentioned BVH above when discussing the RT core. BVH stands for boundary volume hierarchy and it works like this. For ray tracing, you need to send out a ray and see where that triangle you project intersects with an object in a scene. You could do that one by one and “walk” along this 2D projection to cast your rays, but this is inefficient.
For this, you use BVH. Instead of checking each pixel to see if it intersects with an object in the scene, you take all the objects in a scene and put them volumes (think of a box). If the ray you are casting does not intersect with any of those boxes, then you can ignore that area. You don’t need to waste your time and computation power casting rays in that direction anymore because you know nothing is there.
If the ray that’s cast does intersect with one of those boxes, then you know to cast more rays in this direction. So now you move into the next set of smaller boxes inside that initial big box and repeat the process, thereby checking each of these hierarchy levels.
The RT core allows for all this math to take place and enables the acceleration of all these calculations. Compared to Volta, Turing is 6x more efficient when it comes to these kinds of calculations.

Nvidia also discussed DLSS, or deep learning super sampling. DLSS is done by leveraging deep learning to take a lower resolution image and create a higher resolution image. You can also take an incomplete image use DLSS to complete the missing pieces.
Meaning, in theory, you can run a high end game at 1080p but leverage DLSS to run it in a psuedo-4K at super high framerates. I can easily see Nvidia leveraging DLSS in their cloud service, GeForce Now.
Compared to TAA (temporal antialiasing), DLSS provides a much cleaner accurate image. Epic’s Infiltrator demo was running a single Turing card using 4K at 60fps, compared to a 1080 Ti that would run it at 30-something fps. Digital Foundry confirmed that in a behind closed doors demo, they saw the Infiltrator DLSS demo running side-by-side at 4K on a GTX 1080 Ti and RTX 2080 Ti.
Framerates for the 1080 Ti were around 35fps with the 2080 Ti delivering around twice that throughout the demo. Keep in mind, this is a repeatable demo, meaning that this demo will run along the same path each time making it easy to optimize for. I’m curious to see real-world performance in games leveraging DLSS. Currently, these are the list of games that are confirmed to support DLSS.

Naturally, because of just how unprecedented and new all this technology is, people will needlessly freak out. Articles like this raise performance concerns when utilizing these technologies and naturally begin to worry people.
I believe that the people who’ll get upset at sub-60fps at 1080p with ray tracing enabled in games like Tomb Raider just fundamentally fail to grasp the magnitude of what exactly is going on under the hood.
Keep in mind, film CGI leverage ray tracing and it can take hours or days of render time per frame. The fact that we now have a single graphics card that can do this at real-time at even 30fps is a monumental milestone in PC graphics.
This is just the first generation with this technology. The game needs to be further optimized before launch. Drivers need to be released. People need to just understand the bigger picture. Their worry stems from an ignorance that really is the onus of Nvidia and media to mitigate and educate.
However, this still raises concerns of real-world “normal” rasterization performance. Typically, when we measure performance, we do so by comparing the relativistic increase of the new product compared to the old product.
Nvidia deliberately didn’t show off metrics or talk about such performance, so until we see actual benchmarks, it’s difficult for us to gauge this. Cynically, you can say that they didn’t discuss this because perhaps Turing isn’t as big an increase as people expect.
Conversely, the SMs in Turing can perform independent FP and integer operations — something previous generations couldn’t do. The SMs also feature a new unified cache architecture with double the bandwidth of Pascal. In this sense, one Turing SM is more capable and performant than one Pascal SM. But at end of the day, we simply need to wait for benchmarks and real-world testing.

To that end, Nvidia tweeted this link a few days after their keynote, citing real-world performance gains in various games,
But right out of the box it gives you a huge performance upgrade for games you’re playing now. GeForce RTX GPUs deliver 4K HDR gaming on modern AAA titles at 60 frames per second — a feat even our flagship GeForce GTX 1080 Ti GPU can’t manage.
These framerates above were captured at 4K HDR on an RTX 2080. Anecdotally, I achieve 45fps at 4K HDR in Final Fantasy XV on a GTX 1080 Ti overclocked to 2 GHz, so seeing a 60fps figure for that game on the RTX 2080 (not even the highest-end 2080 Ti) is great to see.
Of course, take this with a grain of salt. This is Nvidia themselves providing performance numbers, and we have no indication on whether or not the 2080 was overclocked. Additionally, we have no idea what quality presets at which these games were tested.
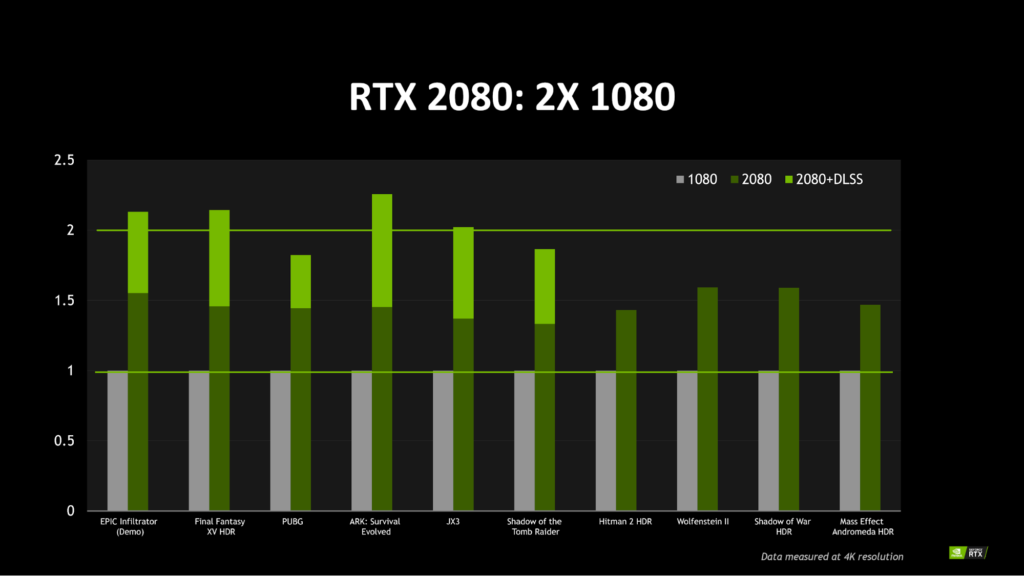
This next chart is most interesting. Essentially, Nvidia is normalizing the GTX 1080 performance per game at 4K in order to show the boost in proportionate performance of the RTX 2080 for that same game.
Some games see a 2x increase when leveraging DLSS, which tells me that DLSS data is delivered via driver updates. This is truly massive. In other games, however, we’re seeing a 50% boost in performance at 4K when not leveraging DLSS, still a massive increase. In this scenario, if you’re experiencing 45fps on a GTX 1080, you can expect 67fps on an RTX 2080 without DLSS. With DLSS, that framerate goes up to 90fps.
With this in mind, we can perform simple math to estimate the potential further increase from a card like the 2080 Ti. Providing that the 2080 Ti is roughly 30% more powerful in compute compared to the 2080, we can estimate to see around a 30% uplift in performance. So if you get 60fps at 4K with the 2080, you can estimate to expect 78fps on a 2080 Ti.
Once again, take this with a grain of salt. We will need to wait for independent benchmarks for all these cards. But even if Nvidia’s performance claims here are a gross exaggeration and realistically we can only expect a 30% boost over a 1080 sans DLSS, it’s still a big leap in performance all the same. Suddenly, 4K 144Hz monitors make sense…if real-world independent testing corroborates Nvidia’s performance claims.
This begs the question: Why didn’t Nvidia discuss this during their keynote when they knew they had everyone’s attention and that people would want to know this information? They wanted to talk up ray tracing. That’s the simple answer. Ray tracing markets better than “50% boost in performance.” Still, to me this showcases a dissonance between what Nvidia wants to discuss versus the information normal people need to hear.

To round this all off, PC gamers are accustomed to high resolutions and high framerates. We are used to having our high resolution cake and eating it too at deliciously high framerates. PC gamers will need to accept the fact that ray tracing is just on a completely different level, requiring never before seen computation.
This means that PC gamers will also need to accept lower framerates. Keep in mind, PC gamers will always have the option to disable it if they want their framerates high. But, in my opinion, this hit is absolutely worth it if it means more physically accurate and immersive games.
This is how the envelope is pushed. We must constantly push technology forward. That is how we achieve progress. Some people will always say that graphics don’t matter. But these are the same people who continue to buy graphics cards and consoles generation on generation. Additionally, this is such an embarrassingly backwards mentality. Without progress, you remain stagnant. And in the real-world, when you’re stagnant, you’re moving backwards.
Regarding ray tracing, this is just the beginning. I’m extremely curious to see the new gameplay implications this could allow. One can imagine seeing an enemy soldier in a reflection running towards you in Battlefield V and then reacting to it. One can also imagine how developers can leverage Tensor cores to create better AI.

The reality is that only a fraction of consumers will have this technology available to them. Meaning, developers will be catering to a tiny subset. They’ll still have to create the baked global illumination methods that currently exist, in addition to implementing ray tracing. How and if developers want to leverage this is up to them, but I certainly hope to see widespread adoption.
Additionally, this is using Nvidia’s bespoke platform, meaning AMD users won’t be able to utilize this. Even if they could though, their GPUs simply aren’t engineered for ray tracing. Nvidia had to create dedicated hardware to enable this.
And right now, AMD is doing nothing. Like I mentioned in my previous article, it’s one thing to rely on your strength (Ryzen CPUs), but to, at least outwardly, seemingly not compete in the GPU space begs the question: Why is AMD still in it? Do they even want to be in it? I don’t ask these questions lightly, but as someone who cares about this industry, I cannot help but wonder.
Regarding consoles, there is absolutely no way the next gen Xbox and PlayStation will be able to do ray tracing. The so-called “enhanced” consoles in the Xbox One X and PS4 Pro can barely do native 4K, nevermind 60fps at that resolution. With the inevitable expected hit to performance that ray tracing will bring, there is simply no chance the next gen consoles will be even remotely capable of this. In fact, I don’t expect consoles to be capable of performing ray tracing for at least two more generations. In short, PC games will be on a completely different level for the foreseeable future, provided we see developer adoption of RTX.

Everything coming out of Gamescom from Microsoft and Sony legitimately looks like child’s play compared to the technology on display from Nvidia. Tweets from Microsoft said Battlefield V will be the “most intense, immersive Battlefield,” deserving of an Xbox One. I just have to sit there and laugh while patting these console manufacturers on the head in a patronizing manner.
Not 24 hours before was ground breaking technology on display from Nvidia, yet Microsoft is claiming that Battlefield V is so immersive that it deserves an Xbox One — a console which consistently struggles to hit even 1080p with its bigger brother failing to consistently hit 4K in most games, nevermind 60fps. It just shows me the absolute cavernous expanse between consoles today and modern PC technology, an expanse which continues to get wider and wider.
In the end, I fundamentally believe we are just at the beginning of a completely new era of PC gaming. This sounds an awful lot like hyperbole, and I certainly don’t blame you for thinking so. After all, how many times have we heard that before?
The difference here is that ray tracing, unlike 3D and VR, has long been the holy grail of PC graphics. The desire to emulate the real world has been there since the dawn of PC gaming. All these methods such as physically based rendering, ambient occlusion, and the like are proof of this desire to emulate the real world. I believe ray tracing in PC graphics is still at its infancy, but the genuinely revolutionary leap in hardware and software engineering done by Nvidia simply cannot be downplayed in the slightest. This is truly a remarkable achievement and an inflection point in PC graphics and real-time rendering. I’m so very much looking forward to what happens next.





